
Artificial intelligence today is powered by enormous mathematical engines. Behind every large language model, every image generator, and every recommendation system lies one dominant operation: matrix multiplication. But here’s the real question how do AI GPUs execute trillions of these operations per second without collapsing under computational load?
The answer lies in Tensor Core architecture.
If memory hierarchy feeds the engine, tensor cores are the combustion chamber. They are specialized compute units inside modern GPUs designed specifically to accelerate matrix multiply-accumulate (MMA) operations at massive scale. Without them, modern AI training at trillion-parameter scale would be economically and physically impractical.
In this deep dive, we will unpack how tensor cores work internally, how they interact with memory systems, how precision formats like FP16 and FP8 transform throughput, and why tensor cores not general CUDA cores are the true heart of AI acceleration.
Let’s start at the foundation.
What Are Tensor Cores?
Tensor cores are specialized hardware units inside modern NVIDIA GPUs (starting from Volta architecture) designed to accelerate matrix multiply-accumulate operations, the mathematical backbone of deep learning.
Traditional GPUs relied solely on CUDA cores. CUDA cores are general-purpose parallel arithmetic units capable of handling many workloads graphics shading, physics simulation, scientific computing, and AI tasks. But they were not optimized specifically for the dense matrix operations that dominate neural networks.
And here’s the problem.
AI is not random arithmetic. It is structured linear algebra. During training, neural networks repeatedly compute operations of the form:
This is called matrix multiply-accumulate (MMA).
CUDA cores can perform these operations, but inefficiently compared to hardware designed specifically for them. Tensor cores execute these matrix blocks in fixed-size tiles at the hardware level, dramatically increasing throughput.
Starting from NVIDIA Volta (V100), tensor cores began accelerating FP16 matrix operations. Later generations (Turing, Ampere, Hopper) expanded support to:
- FP16
- BF16
- TF32
- FP8
- INT8
Each generation improved throughput and energy efficiency.
The evolution is clear: general compute cores were no longer enough. AI demanded purpose-built silicon.
Why Matrix Multiplication Dominates AI
At its core, AI is linear algebra wrapped in nonlinear activation functions.
Every neural network layer whether convolutional, fully connected, or attention-based ultimately reduces to matrix multiplication. Even transformer architectures, the foundation of large language models, are dominated by GEMM operations.
What Is GEMM?
GEMM stands for General Matrix Multiply. It represents the core operation:
In AI training:
- A = input activations
- B = weights
- C = output activations
Now multiply that across:
- Billions of parameters
- Thousands of layers
- Millions of tokens
The computational load becomes astronomical.
FLOPS Explosion
Modern AI GPUs advertise numbers like:
- 1,000+ TFLOPS (FP8 tensor performance)
- Hundreds of TFLOPS (FP16 performance)
These numbers are not marketing fluff they represent how many floating-point operations per second the tensor cores can sustain.
But raw compute is meaningless if memory cannot feed it. This is exactly where the AI memory bottleneck emerges when tensor cores wait for data instead of computing.
Matrix math is compute-heavy, but it is also data-hungry.
Tensor cores solve the compute side of the equation.
Memory hierarchy solves the data side.
Together, they define AI performance.
How Tensor Cores Work Internally
Now we go deeper inside the silicon.
Tensor cores do not operate on single scalar values like traditional ALUs. Instead, they process small matrix tiles typically 4×4, 8×8, or 16×16 blocks depending on architecture.
This tiling is critical.
Warp-Level Execution
In NVIDIA GPUs, execution happens in groups of 32 threads called a warp. When a warp executes a matrix instruction, tensor cores operate on fragments of matrices distributed across threads.
Each thread contributes part of the matrix tile stored in registers. The warp collectively feeds data into the tensor core.
MMA Units
Inside each Streaming Multiprocessor (SM), tensor cores contain dedicated MMA pipelines. These pipelines:
- Fetch matrix fragments from registers
- Perform fused multiply-accumulate
- Store results back into registers
This happens in a few cycles massively parallelized across dozens of tensor cores per SM.
Register Tiling
Register tiling is crucial. Instead of constantly accessing L1 or L2 cache, matrix fragments are staged in registers. This reduces latency and maximizes data reuse.
Registers → Tensor Core → Accumulator → Registers.
Data locality is everything.
Precision Formats in Tensor Cores
Precision determines performance.
Higher precision means more bits per number, more accuracy but lower throughput.
Lower precision means faster computation and reduced memory bandwidth, but potential numerical instability.
Tensor cores support multiple precision formats:
| Format | Bits | Use Case |
|---|---|---|
| FP32 | 32 | Traditional compute |
| FP16 | 16 | Early AI acceleration |
| BF16 | 16 | Stable training |
| TF32 | 19 (effective) | Hybrid format |
| FP8 | 8 | Next-gen scaling |
Mixed Precision Training
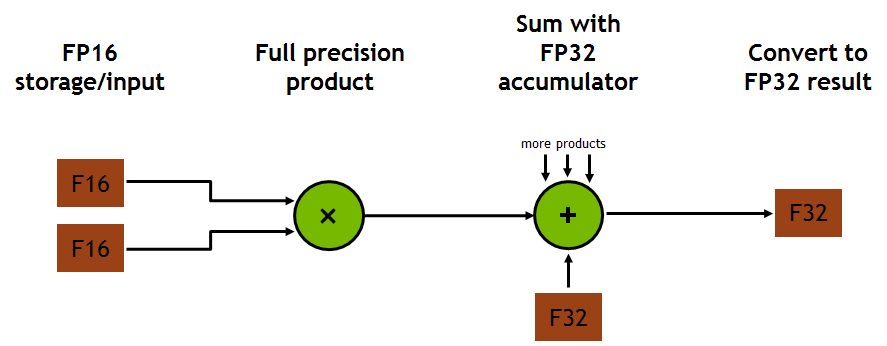
Modern AI training uses mixed precision:
- Compute in FP16 or FP8
- Accumulate in FP32
This preserves numerical stability while dramatically increasing throughput.
FP8 support in Hopper architecture marks a massive leap doubling effective tensor throughput in many workloads.
Precision is no longer just accuracy.
It is performance economics.
NVIDIA Turing Architecture and INT8 GEMM Support
As detailed in NVIDIA’s official Turing architecture in-depth technical overview, the Turing generation introduced expanded Tensor Core capabilities by adding native INT8 support for inference-focused workloads. While Volta primarily optimized Tensor Cores for FP16 training acceleration, Turing shifted architectural focus toward high-throughput inference efficiency designed specifically for production AI deployment.
INT8 GEMM (General Matrix Multiply) support enables Tensor Cores to execute 8-bit integer matrix operations at significantly higher throughput compared to FP32 CUDA cores. Because inference workloads such as computer vision, recommendation systems, and NLP pipelines tolerate lower numerical precision, INT8 reduces memory bandwidth usage and increases operations per watt.
In real-world deployments, Turing-based GPUs can deliver 2× to 4× higher inference performance using INT8 GEMM compared to FP32 execution. This made Turing a critical architectural milestone in scaling production AI systems efficiently.
The architectural progression became clear:
Volta optimized FP16 training,
Turing optimized INT8 inference,
Ampere expanded mixed precision,
Hopper introduced FP8 and sparsity acceleration.
Data Flow from HBM to Tensor Core
Compute is useless without data.
Here’s the exact path:
HBM → L2 Cache → L1 Cache → Registers → Tensor Core → Registers → L2 → HBM
This staged data movement is governed by the AI accelerator memory hierarchy.
HBM provides massive bandwidth (3–5 TB/s).
L2 reduces global access frequency.
L1 increases locality.
Registers feed tensor cores directly.
If any stage underperforms, tensor cores stall.
This tight integration between memory and compute is what defines AI accelerator design.
For a deeper understanding of this layered structure, see our breakdown of the AI accelerator memory hierarchy.
Tensor cores execute.
Memory feeds.
Performance emerges from coordination.
For a deeper look at stacking and bandwidth design, see our Complete HBM architecture explained guide.
Tensor Core vs CUDA Core
The structural difference is profound.
| Feature | CUDA Core | Tensor Core |
|---|---|---|
| Operation Type | Scalar arithmetic | Matrix MMA |
| AI Optimization | Limited | Specialized |
| Throughput | Moderate | Extremely high |
| Precision Support | FP32 dominant | FP16, BF16, FP8 |
CUDA cores are flexible.
Tensor cores are specialized.
For gaming graphics, CUDA cores shine.
For AI training, tensor cores dominate.
Modern GPUs still use CUDA cores for:
- Control logic
- Non-matrix operations
- Pre/post-processing
But the heavy lifting? That’s tensor cores.
Performance Scaling in Modern GPUs
Raw TFLOPS are impressive but utilization matters more.
If tensor cores deliver 1,000 TFLOPS but memory cannot supply data fast enough, effective performance drops.
The ratio between:
Compute Throughput / Memory Bandwidth
determines bottlenecks.
If compute grows faster than bandwidth, we re-enter the AI memory bottleneck territory.
Multi-GPU scaling introduces another layer interconnect bandwidth. Technologies like NVLink extend memory sharing across accelerators, enabling trillion-parameter training.
Scaling AI performance is no longer just about adding cores.
It’s about balancing compute and data flow.
Role of Tensor Cores in LLM Training
Large language models are matrix multiplication machines.
Every transformer layer performs:
- Attention score computation
- Query-Key matrix multiply
- Value projection
- Feedforward expansion
Batch size increases matrix dimensions.
Sequence length increases memory footprint.
Model size increases parameter matrix dimensions.
Tensor cores enable:
- High throughput attention computation
- Efficient gradient backpropagation
- Scalable parameter updates
Without tensor cores, training GPT-scale models would require orders of magnitude more hardware.
Energy Efficiency of Tensor Execution
Data movement consumes more energy than arithmetic.
A tensor core performing an MMA operation is extremely energy efficient compared to moving data across memory tiers.
But:
HBM access = expensive
L2 access = cheaper
Register access = cheapest
The closer data sits to compute, the lower energy per operation.
That’s why AI infrastructure memory energy costs are dominated by data movement, not arithmetic.
Tensor cores maximize FLOPS per watt.
Memory hierarchy minimizes data movement.
Together, they define energy efficiency.
Future of Tensor Processing
The roadmap is clear:
- FP8 scaling
- Structured sparsity acceleration
- Hybrid precision execution
- Chiplet-based compute units
Future architectures may integrate compute and memory more tightly perhaps even moving toward memory-centric compute models.
Tensor cores will evolve, but the principle remains:
AI performance = Matrix throughput × Data availability × Energy efficiency.
Modern GPUs such as those based on the NVIDIA Hopper architecture integrate advanced tensor cores optimized for FP8 precision and sparsity acceleration.
FAQs
How do tensor cores differ from CUDA cores?
Tensor cores specialize in matrix multiply-accumulate operations, while CUDA cores handle general-purpose scalar arithmetic tasks.
Why are matrix operations central to AI?
Neural networks rely on matrix multiplication for layer computation, attention mechanisms, and gradient updates, making linear algebra the core workload.
What precision formats do tensor cores support?
Modern tensor cores support FP16, BF16, TF32, FP8, and INT8 formats, enabling mixed precision training for higher throughput.
How do tensor cores interact with HBM memory?
Data flows from HBM through L2 and L1 caches into registers before reaching tensor cores for execution, then results are written back.
Do all AI workloads require tensor cores?
Most large-scale deep learning workloads benefit significantly from tensor cores, though smaller or non-matrix-heavy tasks may rely more on CUDA cores.
Conclusion
Tensor cores are not just faster arithmetic units.
They are purpose-built matrix engines that transform how AI workloads execute at scale. By specializing in matrix multiply-accumulate operations, supporting mixed precision formats, and tightly integrating with memory hierarchy, tensor cores enable trillion-parameter model training.
Memory feeds the system.
Tensor cores execute.
Performance emerges from balance.
Without tensor cores, modern AI acceleration would stall under its own computational weight.
With them, matrix math becomes scalable infrastructure.