
What Is NVIDIA Hopper Architecture?
The NVIDIA Hopper architecture represents a generational leap in AI accelerator architecture, designed specifically for the era of large-scale generative AI and trillion-parameter models. If Ampere powered the early deep learning boom, Hopper powers the foundation model revolution. It is not merely an incremental GPU upgrade it is a structural redesign focused on compute density, memory bandwidth, scaling efficiency, and precision flexibility.
At its core, Hopper is the architectural backbone behind the NVIDIA H100 GPU architecture, which currently anchors AI data centers worldwide. Named after computer science pioneer Grace Hopper, this generation reflects a philosophical shift in GPU design: from graphics-first acceleration to AI-native infrastructure.
So what changed?
Hopper was engineered around three primary bottlenecks exposed by large language models (LLMs):
- Memory bandwidth saturation
- Precision inefficiency in training
- Multi-GPU scaling limitations
Instead of just increasing CUDA core counts, NVIDIA introduced fourth-generation Tensor Cores, FP8 precision support, the Transformer Engine, HBM3 memory, and NVLink 4.0 all designed to remove systemic AI training constraints.
Unlike traditional GPUs optimized for rasterization or even generic parallel compute, Hopper focuses on matrix math dominance. AI workloads especially transformers are overwhelmingly tensor-based. Hopper recognizes this and doubles down.
The result? Massive throughput gains in both training and inference, improved performance per watt, and better infrastructure scaling across nodes.
In short, NVIDIA Hopper architecture explained simply is this: it is NVIDIA’s purpose-built AI supercomputing architecture for the generative AI era.
Introduction to the Hopper Generation
To understand Hopper, you have to look at the problem landscape that emerged around 2020–2022. Transformer models exploded in size. GPT-3 had 175 billion parameters. Within two years, models crossed the trillion-parameter mark. Suddenly, training runs weren’t measured in hours they were measured in megawatt-hours.
Ampere (A100) was powerful, but it was built before the true generative AI acceleration curve became obvious. It supported FP16 and TF32 extremely well. But transformer workloads revealed inefficiencies:
- Precision formats were still too heavy.
- Memory bandwidth was the dominant bottleneck.
- Inter-GPU communication slowed scaling efficiency.
- Energy consumption per training run skyrocketed.
Hopper was NVIDIA’s answer.
The Hopper H100 GPU architecture introduced a new philosophy: precision agility. Instead of locking models into FP16 or BF16, Hopper introduced FP8 tensor cores. That single change altered the economics of AI training.
Why does that matter?
Because transformers are memory-bound. Reducing numerical precision from 16 bits to 8 bits effectively doubles data throughput for many operations if accuracy can be preserved. Hopper’s Transformer Engine dynamically manages this tradeoff, ensuring stability while maximizing throughput.
But precision alone isn’t enough. Hopper integrates HBM3 memory, boosting bandwidth beyond 3 TB/s in SXM configurations. It expands L2 cache dramatically. It upgrades NVLink to enable multi-terabyte per second GPU-to-GPU bandwidth.
This isn’t a gaming GPU evolution. It’s a data center AI infrastructure redefinition.
Hopper isn’t faster just because it has more cores. It’s faster because it attacks AI bottlenecks at every architectural layer compute, memory, and interconnect.
Why Hopper Replaced Ampere
Architectural transitions in NVIDIA’s roadmap typically follow a pattern: increase compute density, improve efficiency, introduce new instruction capabilities. Hopper breaks that pattern by focusing less on raw transistor scaling and more on workload specialization.
Ampere was exceptional for mixed workloads AI, HPC, and even inference at scale. But once transformer-based AI models became dominant, specific weaknesses emerged:
- Scaling inefficiencies across nodes
- High memory pressure during attention operations
- Precision rigidity in training pipelines
- Limited structured sparsity exploitation
Hopper addresses these systematically.
First, fourth-generation Tensor Cores support FP8, doubling effective math throughput compared to FP16 under many AI workloads. This directly impacts large language model training where matrix multiplications dominate.
Second, Hopper introduces the Transformer Engine a hardware-software co-design innovation. Instead of manually tuning precision across layers, the engine automatically adjusts between FP8 and FP16 based on layer sensitivity. That removes a massive optimization burden from AI engineers.
Third, memory architecture received a significant overhaul. HBM3 replaces HBM2E, pushing memory bandwidth well past previous ceilings. Combined with expanded L2 cache, data reuse improves dramatically, reducing external memory fetches.
Fourth, NVLink 4.0 improves GPU-to-GPU bandwidth substantially. Multi-GPU clusters no longer suffer the same communication penalties seen in large-scale Ampere deployments.
In short, Hopper replaced Ampere because AI workloads evolved faster than Ampere’s architectural assumptions.
It wasn’t about making a bigger GPU.
It was about building a transformer-native compute engine.
Designed for the Generative AI Era
Generative AI isn’t just another workload category it’s structurally different. Transformers demand:
- Massive matrix multiplications
- High-bandwidth memory access
- Large model parallelism
- Long context attention scaling
Traditional GPU designs treat these as generic compute problems. Hopper treats them as first-class architectural priorities.
Let’s break that down.
In transformer models, attention layers dominate runtime. These layers are heavily memory-bound. Data movement not raw compute is often the limiting factor. Hopper’s HBM3 memory subsystem dramatically increases memory bandwidth, while its larger L2 cache reduces memory fetch frequency.
Then there’s precision scaling. In generative AI, not every layer needs FP16 precision. Many operations tolerate lower precision without accuracy degradation. Hopper’s FP8 tensor cores allow throughput to skyrocket without proportional increases in power consumption.
Energy matters. Training GPT-scale models consumes enormous energy budgets. Hopper improves performance per watt significantly compared to Ampere, making large model training economically viable at scale.
Finally, generative AI requires massive multi-GPU clusters. Hopper’s NVLink 4.0 and improved interconnect topologies enable distributed training with reduced communication overhead.
Think of Hopper as an AI data center architecture in silicon form.
It doesn’t just compute faster.
It moves data smarter.
It scales cleaner.
It trains larger models more efficiently.
And in the generative AI era, that combination defines architectural relevance.
H100 as the Flagship Implementation
When people search for NVIDIA Hopper architecture explained, what they’re really trying to understand is the H100 GPU architecture, because H100 is Hopper’s physical embodiment. Hopper is the blueprint. H100 is the machine built from it.
The NVIDIA H100 isn’t just a successor to the A100 it’s a redefinition of what a data center GPU looks like. Built on TSMC’s 4N process, the H100 packs roughly 80 billion transistors. But raw transistor count is only part of the story. The architectural layout focuses heavily on AI matrix throughput, memory bandwidth density, and interconnect scaling.
The H100 comes in multiple form factors:
- SXM (for high-performance AI servers with maximum power envelope)
- PCIe (for broader data center deployment flexibility)
The SXM variant delivers significantly higher memory bandwidth and NVLink connectivity, making it the preferred configuration for large-scale AI training clusters.
Key highlights of H100:
- Fourth-generation Tensor Cores
- FP8 precision support
- Up to 3+ TB/s HBM3 memory bandwidth (SXM)
- NVLink 4.0 support
- Massive L2 cache expansion
But here’s the real shift: H100 isn’t optimized for graphics. It’s an AI accelerator architecture first, and everything else second. CUDA cores are still there, of course but Tensor Cores dominate performance metrics.
Another important addition is confidential computing support for multi-tenant cloud AI environments. As generative AI becomes commercialized, security isolation becomes a first-order architectural requirement.
In practical terms, H100 enables:
- Faster GPT-scale model training
- More efficient inference at scale
- Better performance per watt
- Reduced total cost per training run
If Ampere made hyperscale AI feasible, Hopper makes trillion-parameter AI sustainable.
Key Architectural Innovations in Hopper
Hopper’s strength doesn’t come from one breakthrough it comes from coordinated architectural upgrades across compute, memory, and scaling layers. It’s like upgrading the engine, transmission, fuel system, and aerodynamics of a car simultaneously. The performance jump isn’t linear. It’s systemic.
Three innovations define Hopper:
- Fourth-generation Tensor Cores
- Transformer Engine
- Memory and interconnect evolution
Each of these targets a specific AI bottleneck.
Traditional GPU improvements often focus on core counts. Hopper focuses on math efficiency per bit moved. That’s crucial because modern AI training is constrained more by memory bandwidth and communication overhead than by raw arithmetic capacity.
Hopper also enhances structured sparsity acceleration. Sparsity allows skipping zero-value computations in neural networks, effectively increasing throughput without increasing physical compute units. When combined with FP8 precision and dynamic scaling, this yields exponential efficiency improvements in optimized models.
From an architectural authority perspective, Hopper represents a maturity stage in AI accelerator design. It recognizes that:
- Precision is dynamic.
- Memory is dominant.
- Scaling is everything.
Let’s dissect the most transformative component nextthe fourth-generation Tensor Cores.
Fourth-Generation Tensor Cores
Tensor Cores are the heart of NVIDIA’s AI dominance. With Hopper, they enter their fourth generation and this iteration isn’t incremental. It’s transformational.
In Ampere, third-generation Tensor Cores supported FP16, BF16, TF32, and sparsity acceleration. Hopper expands this with native FP8 support, effectively doubling math throughput in many AI workloads.
Here’s why that matters.
AI training involves repeated matrix multiplications. The smaller the numerical format (without losing accuracy), the more data you can push through the same hardware. FP8 cuts data size in half compared to FP16. That means:
- Twice the data per memory fetch
- Higher effective bandwidth
- Lower energy per operation
Hopper Tensor Cores also improve sparsity acceleration. Structured sparsity allows skipping zeroed weights in neural networks. Hopper enhances sparse computation throughput, improving performance when models are pruned or sparsified.
Key improvements include:
- FP8 support (E4M3 and E5M2 formats)
- Higher throughput per SM
- Improved operand reuse
- Better pipeline scheduling
These cores are deeply optimized for transformer-based workloads. Attention layers, feed-forward networks, and projection matrices all benefit.
Think of fourth-generation Tensor Cores as hyper-specialized matrix engines tuned specifically for the generative AI era.
They don’t just compute faster.
They compute smarter, leaner, and more efficiently.
FP8 Precision Support

FP8 is arguably the most disruptive feature of the H100 GPU architecture. Before Hopper, 16-bit precision (FP16/BF16) was the sweet spot for training stability and performance. Hopper halves that.
But here’s the challenge: lower precision risks accuracy loss and training instability. That’s where Hopper’s design shines.
FP8 in Hopper supports two formats:
- E4M3 (more mantissa precision)
- E5M2 (larger dynamic range)
This flexibility allows different layers of a neural network to use different numerical representations depending on sensitivity.
Why is FP8 powerful?
- It reduces memory footprint.
- It doubles throughput relative to FP16 in many operations.
- It lowers power consumption.
- It increases effective memory bandwidth.
In transformer-heavy workloads, matrix multiplications dominate runtime. With FP8, throughput scaling can reach dramatic levels, especially when combined with sparsity acceleration.
From an infrastructure perspective, FP8 changes cluster economics. If training time drops significantly, cloud GPU utilization improves. Energy consumption per training job decreases. Model iteration cycles accelerate.
FP8 isn’t just a new format.
It’s a cost-efficiency multiplier for AI training at scale.
Transformer Engine Explained
The Transformer Engine is Hopper’s secret weapon.
Introducing FP8 alone isn’t enough. AI engineers would need to manually manage precision across layers, test stability, and debug training divergence. That’s operationally painful.
Instead, NVIDIA integrated the Transformer Engine, a hardware-software co-design system that automatically manages precision scaling.
Here’s how it works:
- Monitors layer-level statistics
- Dynamically switches between FP8 and FP16
- Maintains model accuracy
- Maximizes throughput where safe
In other words, it brings adaptive precision into hardware.
This matters because transformers aren’t uniform. Some layers tolerate lower precision extremely well. Others require higher dynamic range. The Transformer Engine makes these decisions dynamically during runtime.
Why does this matter for LLM training?
Because manual precision tuning at trillion-parameter scale is impractical. Automation removes complexity while unlocking FP8 benefits.
It’s similar to automatic transmission in cars. You could shift gears manually but why would you, if automation is faster and more efficient?
The Transformer Engine turns Hopper into a precision-adaptive AI accelerator.
That’s architectural intelligence not just hardware muscle.
Hopper Memory Subsystem
If Tensor Cores are the brain of Hopper, the memory subsystem is the bloodstream.
AI workloads are memory-bound. No matter how powerful compute units are, if data can’t reach them fast enough, performance stalls. Hopper addresses this aggressively.
The H100 integrates HBM3 memory, dramatically increasing memory bandwidth compared to Ampere’s HBM2E. In SXM configurations, bandwidth exceeds 3 terabytes per second.
Let that sink in.
That’s trillions of bytes per second feeding matrix engines.
But Hopper doesn’t stop there.
It significantly expands L2 cache capacity, reducing reliance on external memory fetches. This improves data locality and reduces latency for frequently accessed tensors.
The memory hierarchy in Hopper looks like this:
- On-chip registers
- Shared memory
- Expanded L2 cache
- HBM3 memory
Each layer is optimized to reduce bottlenecks in transformer workloads.
The combination of:
- FP8 precision
- Higher memory bandwidth
- Larger cache
- Optimized scheduling
creates a system where compute units remain saturated far more consistently than in previous architectures.
In large-scale AI, memory is often the true performance limiter.
Hopper treats it like a first-class citizen.
HBM3 Integration in H100
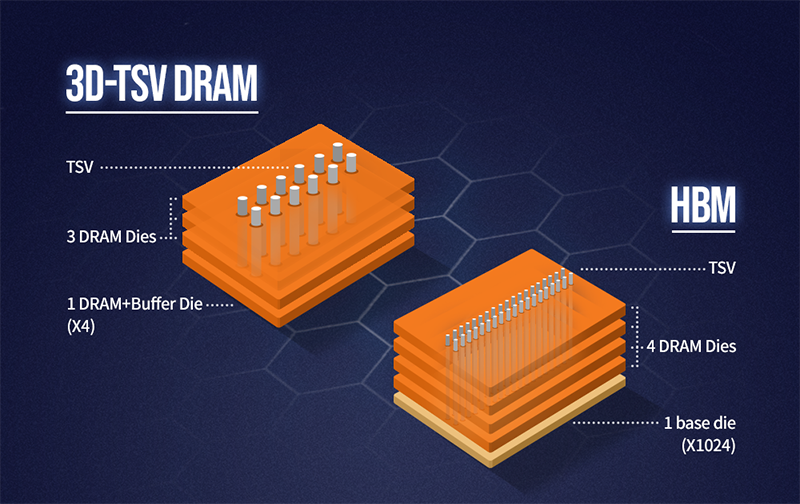
HBM3 in H100 represents a significant leap in AI memory architecture.
Compared to HBM2E used in A100, HBM3 offers:
- Higher data rates
- Increased stack density
- Lower energy per bit transferred
This directly addresses the AI memory bottleneck. Large models require massive parameter movement during forward and backward passes. If memory bandwidth lags, training slows regardless of compute power.
HBM3 enables:
- Faster gradient updates
- Improved attention throughput
- Better scaling across model parallel shards
Physically, HBM3 uses stacked DRAM dies connected via TSVs (Through-Silicon Vias) on a silicon interposer. This design reduces latency and increases bandwidth density compared to traditional GDDR memory.
From a system perspective, HBM3 is one of the main reasons Hopper can sustain FP8 tensor core throughput without starving compute units.
Compute and memory must evolve together.
Hopper proves that.
NVIDIA H100 Memory Bandwidth
Memory bandwidth is one of the most critical performance metrics in AI accelerator architecture. In the H100 SXM variant, bandwidth surpasses 3 TB/s. That’s a dramatic increase over Ampere.
Why is this important?
Transformer models repeatedly access large parameter matrices. During attention computation, data movement often dominates execution time.
Higher bandwidth means:
- Reduced training step time
- Better GPU utilization
- Lower idle compute cycles
- Faster convergence cycles
Bandwidth doesn’t just improve speed it improves cluster economics. If GPUs finish tasks faster, fewer nodes are required to complete large-scale training jobs.
In real-world deployments, memory bandwidth often defines scaling efficiency more than theoretical FLOPS.
Hopper’s memory subsystem ensures that its fourth-generation Tensor Cores remain fully fed.
In AI infrastructure, starvation is inefficiency.
Hopper minimizes starvation.
L2 Cache Expansion
One of the most underrated yet impactful upgrades in the NVIDIA Hopper architecture is the massive expansion of L2 cache. While FP8 Tensor Cores and HBM3 dominate headlines, cache hierarchy optimization is what quietly keeps those compute engines saturated.
In the H100 GPU architecture, NVIDIA significantly increased L2 cache capacity compared to Ampere. Why does this matter?
Because modern transformer workloads exhibit high data reuse patterns. Attention mechanisms repeatedly access key and value matrices. Feed-forward networks reuse intermediate activations. When frequently accessed tensors remain closer to the compute cores, memory latency drops dramatically.
Think of L2 cache as a staging area between ultra-fast on-chip memory and high-bandwidth external HBM3. The more data you can keep inside this staging zone, the fewer expensive external memory fetches you perform.
Here’s what expanded L2 cache enables:
- Reduced HBM traffic
- Lower memory latency
- Improved effective bandwidth
- Better power efficiency
In large language model training, memory movement consumes more energy than arithmetic operations. So improving cache locality doesn’t just increase speed it reduces power draw per training step.
Another important point: as models scale in parameter count, tensor sizes increase. Without larger cache, memory pressure compounds. Hopper’s expanded L2 helps mitigate that growth curve.
In AI accelerator architecture, performance isn’t just about how fast you compute it’s about how efficiently you move data. Hopper’s L2 expansion directly targets that reality.
It’s not flashy.
But it’s foundational.
Memory Hierarchy Improvements
The Hopper memory subsystem isn’t just faster it’s more intelligently layered. AI workloads demand a carefully balanced hierarchy that minimizes bottlenecks across compute and storage tiers.
Let’s break down Hopper’s memory hierarchy:
- Registers (fastest, smallest)
- Shared memory per SM
- Expanded L2 cache
- HBM3 high-bandwidth memory
Each layer plays a specific role in sustaining AI throughput.
Registers and shared memory handle warp-level operations and small tensor fragments. L2 cache acts as a high-capacity buffer for reused activations and weight tiles. HBM3 provides massive bandwidth for large model parameters and gradients.
The critical improvement in Hopper is coordination between these layers. Data movement is optimized to reduce unnecessary round trips to HBM. The scheduling pipeline improves operand reuse within SMs (Streaming Multiprocessors), minimizing latency penalties.
Why does this matter for AI engineers?
Because large transformer models are inherently memory-intensive. Self-attention scales quadratically with sequence length. Without optimized hierarchy management, memory becomes the dominant limiter long before compute peaks.
Hopper’s architecture aligns memory flow with tensor core throughput. That alignment is what allows FP8 acceleration to actually translate into real-world performance gains.
In short:
Compute speed is meaningless without memory orchestration.
Hopper finally treats memory hierarchy as a performance engine not just storage plumbing.
NVLink and Multi-GPU Scaling in Hopper
Single-GPU performance is impressive. But generative AI at scale isn’t trained on one GPU. It’s trained across hundreds or thousands of GPUs working in synchronization.
That’s where NVLink Hopper becomes critical.
Hopper introduces NVLink 4.0, dramatically increasing GPU-to-GPU bandwidth. This is essential for distributed data parallelism, tensor parallelism, and pipeline parallelism used in large model training.
Why does interconnect matter so much?
Because when training trillion-parameter models:
- Gradients must synchronize across nodes.
- Model shards must communicate continuously.
- Attention layers require cross-partition data exchange.
If interconnect bandwidth lags, GPUs sit idle waiting for synchronization.
NVLink 4.0 increases total GPU-to-GPU bandwidth significantly compared to Ampere’s NVLink 3. This reduces communication overhead and improves scaling efficiency.
In practical deployments:
- Multi-GPU clusters scale closer to linear.
- Communication latency drops.
- Training throughput increases.
- Infrastructure utilization improves.
Hopper isn’t just about faster individual GPUs.
It’s about enabling AI supercomputers.
NVLink 4.0 Architecture
NVLink 4.0 is a structural redesign of GPU interconnect bandwidth. In Hopper-based systems, GPUs connect through high-speed NVLink fabric, often coordinated with NVSwitch for full-mesh topologies.
Key advantages include:
- Higher aggregate bandwidth per GPU
- Improved signal efficiency
- Reduced synchronization latency
- Better scalability across racks
When multiple H100 GPUs are connected via NVLink, data can move between them at multi-terabyte per second rates. This is essential for tensor parallel workloads, where weight matrices are partitioned across devices.
Without high-bandwidth interconnect:
- Model parallel training stalls.
- Gradient synchronization becomes a bottleneck.
- Cluster scaling efficiency collapses.
NVLink 4.0 helps preserve near-linear scaling efficiency across multi-GPU systems.
Think of it this way:
If Tensor Cores are the engine, and HBM3 is the fuel system, NVLink is the highway connecting engines together.
Hopper builds a wider highway.
Distributed Training Efficiency
Large-scale AI training involves different parallelization strategies:
- Data parallelism
- Tensor parallelism
- Pipeline parallelism
Each requires constant communication between GPUs.
Hopper improves distributed training efficiency through:
- Higher NVLink bandwidth
- Improved scheduling
- Better memory coordination
- Precision-aware gradient scaling
When GPUs communicate faster, they spend less time idle. That directly increases effective FLOPS utilization across clusters.
In real-world LLM training, communication overhead can consume a large percentage of runtime. Hopper reduces that percentage, allowing compute resources to focus on forward and backward passes instead of synchronization.
For AI infrastructure architects, this translates to:
- Faster time-to-train
- Lower cost per training run
- Higher GPU cluster utilization
Scaling inefficiency is one of the hidden costs of generative AI. Hopper’s architecture minimizes that tax.
Multi-Node AI Scaling
Beyond a single server, Hopper integrates into large AI supercomputing clusters. Multi-node scaling depends not only on NVLink but also on networking stacks like InfiniBand and optimized NCCL communication libraries.
Hopper’s improvements ensure:
- Efficient cross-node gradient reduction
- Stable trillion-parameter model training
- Better pipeline parallel scheduling
In hyperscale environments, hundreds of H100 nodes can be connected to train frontier models.
What makes Hopper ideal for this environment?
- Precision flexibility (FP8)
- High memory bandwidth
- Strong interconnect
- Optimized communication libraries
Together, these enable AI clusters that were previously impractical.
Hopper is not just a GPU.
It’s a building block for AI supercomputers.
Hopper vs Ampere Architecture Comparison
To truly understand Hopper, we need to contrast it directly with Ampere. The improvements aren’t cosmetic they’re structural.
Feature Comparison Table
| Feature | Ampere (A100) | Hopper (H100) |
|---|---|---|
| Tensor Core Generation | 3rd | 4th |
| FP8 Support | No | Yes |
| Memory Type | HBM2E | HBM3 |
| Memory Bandwidth | ~2 TB/s | 3+ TB/s |
| NVLink | Gen 3 | Gen 4 |
| Transformer Engine | No | Yes |
| L2 Cache | Smaller | Significantly Expanded |
The biggest differentiators:
- Native FP8 tensor cores
- Transformer Engine automation
- HBM3 bandwidth leap
- NVLink 4 scaling improvement
Ampere was powerful and versatile. Hopper is specialized and optimized for transformer-dominated workloads.
If Ampere was built for AI growth…
Hopper was built for AI explosion.
Performance and Efficiency Contrast
Performance gains in Hopper aren’t limited to peak FLOPS metrics. Real-world AI workloads see improvements due to combined effects of:
- Precision reduction
- Memory bandwidth increase
- Cache optimization
- Interconnect scaling
FP8 throughput scaling allows certain transformer operations to achieve significantly higher effective performance compared to FP16-based pipelines in Ampere.
Energy efficiency also improves. Because FP8 reduces data movement and arithmetic complexity, performance per watt increases in optimized workloads.
For data center operators, this matters deeply.
Energy is now a limiting factor in AI scaling. Training frontier models consumes enormous power budgets. Hopper improves energy efficiency without sacrificing accuracy thanks to the Transformer Engine.
In summary:
Hopper doesn’t just outperform Ampere.
It rebalances compute, memory, and communication for the generative AI era.
Performance Gains in AI Training & Inference
When evaluating the NVIDIA Hopper architecture explained from a practical standpoint, raw specifications only tell half the story. The real question AI engineers ask is simple: How much faster is it in real workloads?
Hopper’s performance gains emerge from a compound effect:
- FP8 precision doubling effective tensor throughput
- HBM3 memory bandwidth exceeding 3 TB/s
- Larger L2 cache improving locality
- NVLink 4.0 reducing inter-GPU overhead
In transformer-heavy models like GPT-style architectures matrix multiplications dominate runtime. With fourth-generation Tensor Cores and FP8 support, Hopper can deliver dramatically higher effective throughput compared to Ampere when models are optimized for mixed precision.
But training isn’t the only focus. Inference performance also improves significantly. Large language model inference benefits from:
- Reduced memory footprint per token
- Faster attention computations
- Lower latency per request
This is crucial for production deployments where response time directly impacts user experience.
Another key improvement is utilization efficiency. In many Ampere clusters, compute units were occasionally starved due to memory or communication bottlenecks. Hopper reduces those bottlenecks, increasing sustained utilization rates.
It’s like upgrading from a sports car that occasionally stalls in traffic to one that maintains high speed consistently on a multi-lane highway.
The headline isn’t just peak TFLOPS.
It’s sustained, real-world AI acceleration.
FP8 Throughput Scaling
FP8 precision is where Hopper flexes hardest.
By cutting data width from 16 bits to 8 bits (when safe), Hopper effectively doubles arithmetic density for supported operations. That means more operations per clock cycle without proportionally increasing power consumption.
In transformer training, most layers especially feed-forward and projection layers can tolerate lower precision during forward and backward passes. With the Transformer Engine dynamically managing precision, FP8 becomes usable at scale.
Throughput scaling benefits include:
- Higher tokens processed per second
- Faster epoch completion
- Reduced time-to-convergence
- Lower cost per training run
From a systems perspective, FP8 scaling also improves memory bandwidth efficiency. Because data occupies half the space compared to FP16, effective memory throughput increases without physical bandwidth changes.
However, the key is balance. Some layers remain sensitive to precision changes. That’s why Hopper’s hardware-level dynamic precision switching is essential.
Without it, FP8 would be risky.
With it, FP8 becomes transformative.
It shifts the economics of training large language models.
LLM Training Benchmarks
In large language model LLM training scenarios, Hopper shows measurable gains over Ampere in both throughput and scaling efficiency.
Why?
Because LLM training stresses:
- Attention mechanisms
- Matrix multiplications
- Gradient synchronization
- Memory bandwidth
Hopper addresses all four simultaneously.
In optimized training stacks using mixed precision and parallelism strategies, H100 systems can train models significantly faster than A100 clusters with similar node counts.
Key improvements come from:
- Reduced precision overhead
- Higher memory bandwidth
- Improved interconnect scaling
- Better utilization under distributed training
What’s particularly important is scaling efficiency. In multi-node environments, Hopper maintains higher parallel efficiency due to NVLink 4.0 and improved communication scheduling.
For AI research labs and hyperscalers, this translates into:
- Shorter experimentation cycles
- Faster model iteration
- Lower infrastructure cost per milestone
The acceleration isn’t just theoretical it reshapes development velocity.
And in AI, speed of iteration is competitive advantage.
Inference Optimization
While training dominates headlines, inference at scale is where economic impact compounds daily.
Serving large models to millions of users demands:
- Low latency
- High throughput
- Energy efficiency
Hopper improves inference through:
- FP8 acceleration
- Larger cache for parameter reuse
- Better memory bandwidth
- Efficient batching capabilities
Inference workloads often involve repetitive forward passes. Reduced precision lowers memory pressure and increases request throughput per GPU.
For cloud providers, this means:
- Higher query-per-second rates
- Better GPU utilization
- Lower energy per inference
As generative AI moves from experimentation to production, inference efficiency becomes critical. Hopper positions itself not just as a training accelerator but as a scalable inference engine.
The architecture isn’t just about building bigger models.
It’s about serving them sustainably.
Energy Efficiency & AI Infrastructure Impact
Energy is the invisible constraint shaping AI’s future.
Training frontier models consumes massive power budgets. Data centers are increasingly limited not by compute demand, but by energy availability and cooling capacity.
Hopper addresses this by improving performance per watt.
How?
- FP8 reduces arithmetic energy per operation
- Reduced memory movement lowers power draw
- Higher utilization decreases idle consumption
- NVLink efficiency minimizes communication overhead
Compared to Ampere, Hopper can deliver more AI throughput for the same or lower energy expenditure when workloads are optimized.
This matters for:
- Hyperscale cloud providers
- Research institutions
- National AI infrastructure initiatives
AI growth without energy efficiency is unsustainable. Hopper pushes the efficiency curve forward.
Not perfectly but meaningfully.
Performance Per Watt Improvements
Performance per watt is the metric that increasingly defines AI accelerator competitiveness.
Hopper improves this through:
- Lower precision arithmetic
- Reduced memory traffic
- Higher sustained utilization
- Better interconnect efficiency
FP8 operations consume less energy per calculation compared to FP16. When multiplied across trillions of operations, the savings become significant.
Additionally, higher memory bandwidth reduces idle cycles, meaning GPUs spend more time doing useful work instead of waiting.
In large AI clusters, even small efficiency gains translate into:
- Lower operating costs
- Reduced carbon footprint
- Improved scalability
Performance per watt isn’t just a marketing metric.
It’s an infrastructure survival metric.
Data Center Optimization
Hopper’s architectural improvements ripple outward into full data center design.
Because H100 supports higher throughput per GPU, fewer GPUs may be required for equivalent workloads compared to previous generations.
That impacts:
- Rack density planning
- Power provisioning
- Cooling design
- Networking topology
However, Hopper GPUs also have high power envelopes, particularly in SXM configurations. This demands advanced cooling strategies, including liquid cooling in some deployments.
Infrastructure architects must balance:
- Higher performance density
- Increased power per unit
- Improved overall efficiency
Hopper enables more compute per rack but requires thoughtful infrastructure design.
It’s a powerful engine that demands proper housing.
Sustainability Implications
AI sustainability is no longer optional it’s strategic.
With models scaling into trillions of parameters, environmental impact becomes non-trivial. Hopper’s efficiency improvements reduce:
- Energy per training run
- Energy per inference request
- Total compute time
Combined with renewable-powered data centers, Hopper can contribute to greener AI development.
However, sustainability isn’t just about chip efficiency. Supply chain impacts, manufacturing energy costs, and infrastructure footprint all play roles.
Hopper improves the operational side of the equation.
It doesn’t solve sustainability alone but it pushes the trajectory forward.
Role of Hopper in Generative AI & LLM Scaling
Generative AI is the defining workload of this decade.
Hopper was built specifically for it.
Large language models stress hardware in unique ways:
- Massive attention computation
- Long context sequence handling
- Parameter sharding across nodes
- Precision sensitivity
Hopper addresses these via:
- FP8 tensor acceleration
- Transformer Engine dynamic scaling
- High memory bandwidth
- Strong interconnect scaling
GPT-scale training becomes more efficient and more scalable.
As models grow larger, architecture must evolve accordingly. Hopper represents that evolution.
It is the silicon backbone of modern generative AI infrastructure.
Limitations & Tradeoffs
No architecture is perfect.
Hopper introduces tradeoffs:
- High cost per GPU
- Significant power consumption
- Advanced cooling requirements
- Supply constraints
H100 GPUs are expensive and often limited in availability. Their power draw can exceed previous generations, requiring careful infrastructure planning.
Additionally, FP8 optimization requires software adaptation. Not all workloads immediately benefit without tuning.
Hopper is powerful but it demands investment.
It’s cutting-edge infrastructure, not entry-level hardware.
Future of NVIDIA AI Architectures
Hopper sets the stage but evolution continues.
Future architectures are likely to explore:
- Even lower precision formats (FP4?)
- Greater memory integration
- On-package memory expansion
- Memory-compute convergence
- Improved chiplet-based scaling
As generative AI pushes limits, hardware must keep adapting.
If Ampere was growth, and Hopper was acceleration, the next generation may be integration tighter coupling between memory, compute, and networking.
The trajectory is clear:
AI accelerator architecture will become increasingly specialized.
Hopper is a milestone, not an endpoint.
FAQs
What is NVIDIA Hopper architecture?
NVIDIA Hopper architecture is a next-generation AI accelerator architecture designed for large-scale generative AI workloads. It powers the H100 GPU and introduces FP8 Tensor Cores, the Transformer Engine, HBM3 memory, and NVLink 4.0 for improved AI training and inference performance.
What is the H100 GPU used for?
The H100 GPU is primarily used for large language model training, generative AI development, high-performance computing (HPC), and large-scale inference workloads in data centers.
How is Hopper different from Ampere?
Hopper introduces fourth-generation Tensor Cores with FP8 support, HBM3 memory, expanded L2 cache, NVLink 4.0, and the Transformer Engine. Ampere does not support FP8 or dynamic precision scaling.
Does Hopper support FP8 precision?
Yes. Hopper natively supports FP8 precision through fourth-generation Tensor Cores and manages it dynamically using the Transformer Engine.
What is NVIDIA Transformer Engine?
The Transformer Engine is a hardware-software feature in Hopper that dynamically switches between FP8 and FP16 precision during training to maximize performance while preserving model accuracy.
What memory does H100 use?
The H100 GPU uses HBM3 (High Bandwidth Memory 3), delivering over 3 TB/s of memory bandwidth in SXM configurations.
Conclusion
The NVIDIA Hopper architecture explained in full reveals more than a faster GPU. It showcases a systemic redesign for the generative AI era.
With fourth-generation Tensor Cores, FP8 precision, Transformer Engine automation, HBM3 memory, expanded cache, and NVLink 4.0 scaling, Hopper addresses the three defining bottlenecks of modern AI:
- Precision inefficiency
- Memory bandwidth saturation
- Multi-GPU scaling overhead
The H100 GPU architecture stands as the flagship implementation of this philosophy.
Hopper isn’t simply an upgrade over Ampere.
It’s a transformer-native AI accelerator architecture engineered for trillion-parameter scaling.
And in today’s AI race, architecture-level efficiency determines leadership.